I like to have one click deployments for my web code – first to create my infrastructure, and then deploy the website.
But one of the challenges I’ve had in the past is that I’ve needed to make sure my resources (e.g. databases, key vaults etc) have unique names. ARM templates helpfully provide resource functions to generate unique names, but I won’t know what these names are until the infrastructure has been created.
So does that mean I need to first deploy infrastructure, and then introduce a manual step of updating my environment-specific configuration files? Fortunately not – I can populate environment variables in my website with the names of resources, and in my code I just refer to those variables.
The default ARM template for Azure App Services is really useful, but by default it doesn’t have a section for environment variables to be used by the app service, and I find this is usually one of the first things I do when I’m creating an app service. I’ve needed to do this recently, and I decided to write about how I did that.
When you’re creating an Azure App Service in an ARM template, you probably have something that looks similar to the code below – a resource section to create the hosting plan (i.e. the server farm), and a resource section to create the app service to host your site.
"resources": [
{
"apiVersion": "2015-08-01",
"name": "[parameters('hostingPlanName')]",
"type": "Microsoft.Web/serverfarms",
"location": "[resourceGroup().location]",
"tags": {
"displayName": "HostingPlan"
},
"sku": {
"name": "F1",
"capacity": "1"
},
"properties": {
"name": "[parameters('hostingPlanName')]"
}
},
{
"apiVersion": "2015-08-01",
"name": "[variables('webSiteName')]",
"type": "Microsoft.Web/sites",
"location": "[resourceGroup().location]",
"tags": {
"[concat('hidden-related:', resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]": "Resource",
"displayName": "Website"
},
"dependsOn": [
"[resourceId('Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]"
],
"properties": {
"name": "[variables('webSiteName')]",
"serverFarmId": "[resourceId('Microsoft.Web/serverfarms', parameters('hostingPlanName'))]"
}
}
Environment variables can be created at the same time as the app service by adding another resource to the ARM template.
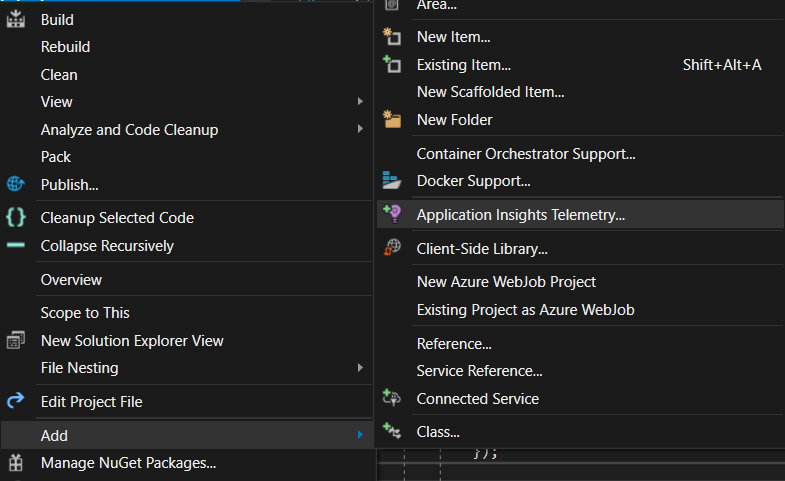
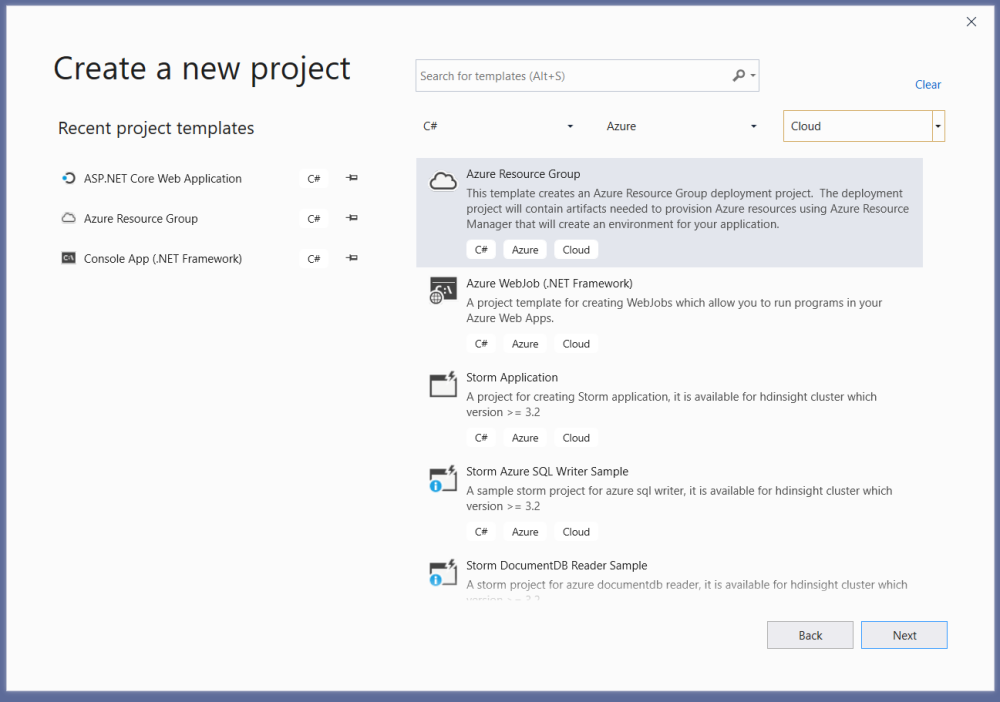
I like to do this through Visual Studio 2019 – as shown below, I open up my ARM project in VS2019, and right click on my template (named WebSite.json) to open the context menu. In the context menu, there’s an item “Show Outline”:

When I click on “Show Outline”, this opens up a new window called “JSON Outline” which shows me what’s in my ARM template – helpfully split into parameters, variables, outputs and resources. As you can see in the image below, I have two resources in my template – the hosting plan and the website.

So if I want to add a new resource, I can right click on the appropriate node, and select “Add New Resource” (as shown below).
It’s important to note that to add environment variables to a website, we have to add the resource to the existing website, so the environment variables will appear as a child object of the website.
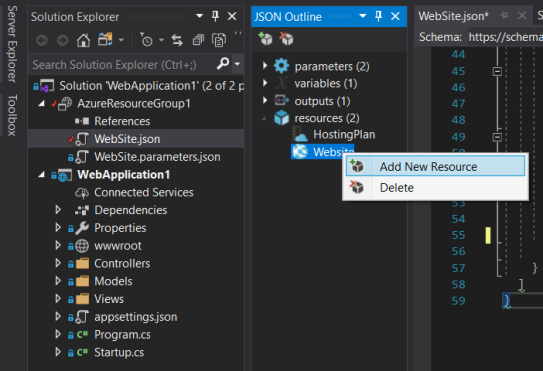
When you click on “Add New Resource”, a window will open that looks like the one below. To add environment variables to the app service, find the “Application Settings for Web Apps” resource (which is highlighted below), and choose a name for the resource – I’ve chosen to call mine “appsettings”.
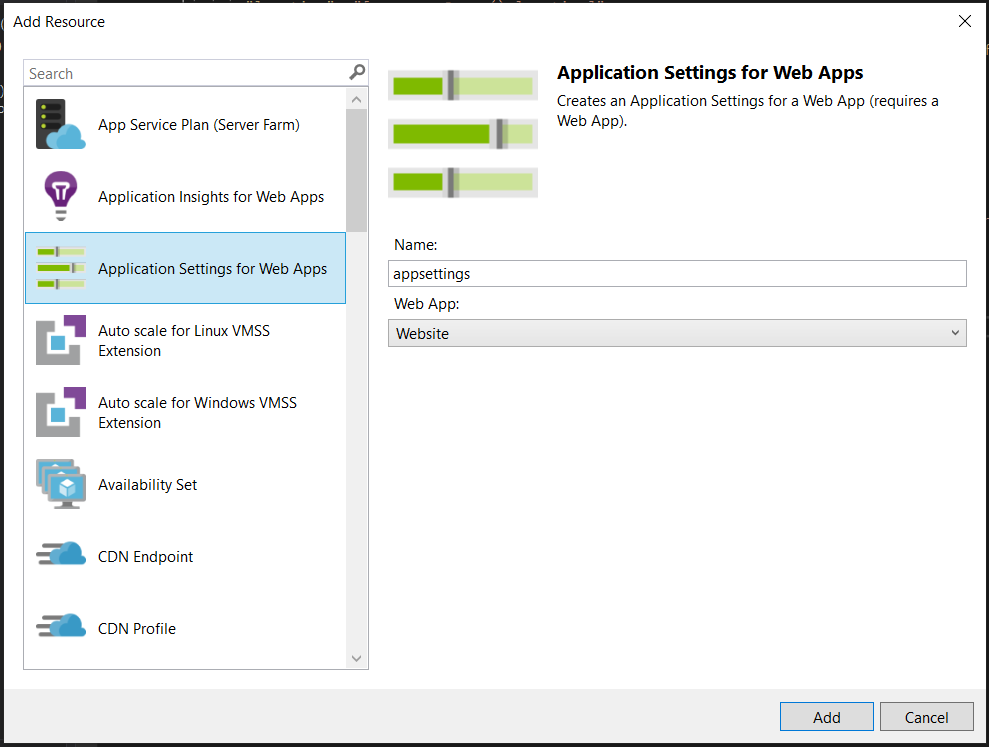
Click on “Add”, and now you’ll see that in your ARM template, your website resource will have an “appsettings” child. This the place where your site’s environment variables will live.
Of course these aren’t the only environment variables in your app service – these are just the ones you’re choosing to add during your infrastructure deployment process.

And this new “appsettings” child object corresponds to the code highlighted in red below:
{
"apiVersion": "2015-08-01",
"name": "[variables('webSiteName')]",
"type": "Microsoft.Web/sites",
"location": "[resourceGroup().location]",
"tags": {
"[concat('hidden-related:', resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]": "Resource",
"displayName": "Website"
},
"dependsOn": [
"[resourceId('Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]"
],
"properties": {
"name": "[variables('webSiteName')]",
"serverFarmId": "[resourceId('Microsoft.Web/serverfarms', parameters('hostingPlanName'))]"
},
"resources": [
{
"name": "appsettings",
"type": "config",
"apiVersion": "2015-08-01",
"dependsOn": [
"[resourceId('Microsoft.Web/sites', variables('webSiteName'))]"
],
"tags": {
"displayName": "appsettings"
},
"properties": {
"key1": "value1",
"key2": "value2"
}
}
]
}
This new resource adds a couple of environment variables by default as examples – “key1” and “key2“.
Obviously these are just placeholders, so let’s consider a real example – what about if I want to deploy the same infrastructure across numerous environments, i.e. use the same ARM template, but parameterise it so that one environment is called “integration”, one is called “demo”, and others could be “staging” or “production”?
Parameterising our ARM template to accept an environment name is straightforward – we just need to add a parameter to our template, as shown below:
"parameters": {
"environmentName": {
"type": "string",
"minLength": 1
}
}
And now we can update the environment variable properties to have a key called “ASPNETCORE_ENVIRONMENT”, with the value set by the process that calls the ARM template.
"resources": [
{
"name": "appsettings",
"type": "config",
"apiVersion": "2015-08-01",
"dependsOn": [
"[resourceId('Microsoft.Web/sites', variables('webSiteName'))]"
],
"tags": {
"displayName": "appsettings"
},
"properties": {
"ASPNETCORE_ENVIRONMENT": "[parameters('environmentName')]"
}
}
]
I usually would call my ARM template using the “Azure Resource Group” deployment task in Azure Pipelines, and I can just specify the value of this variable at each deployment stage as follows:
-environmentName "integration"
Or
-environmentName "demonstration"
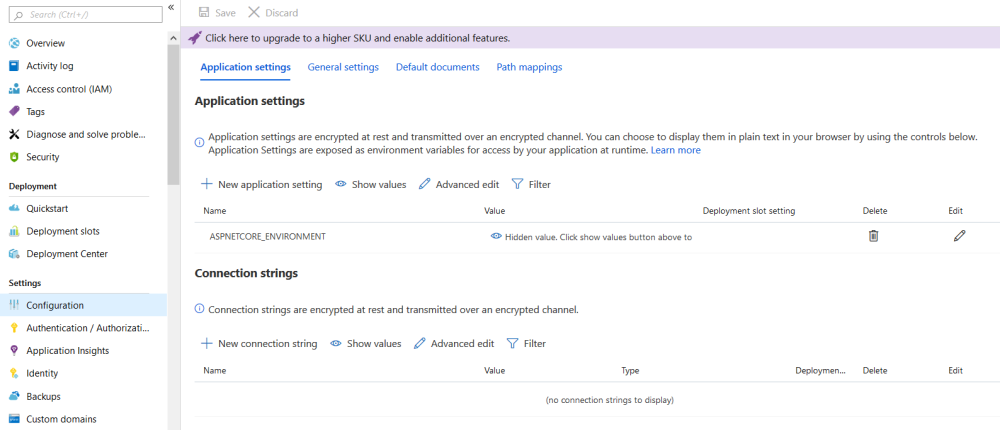
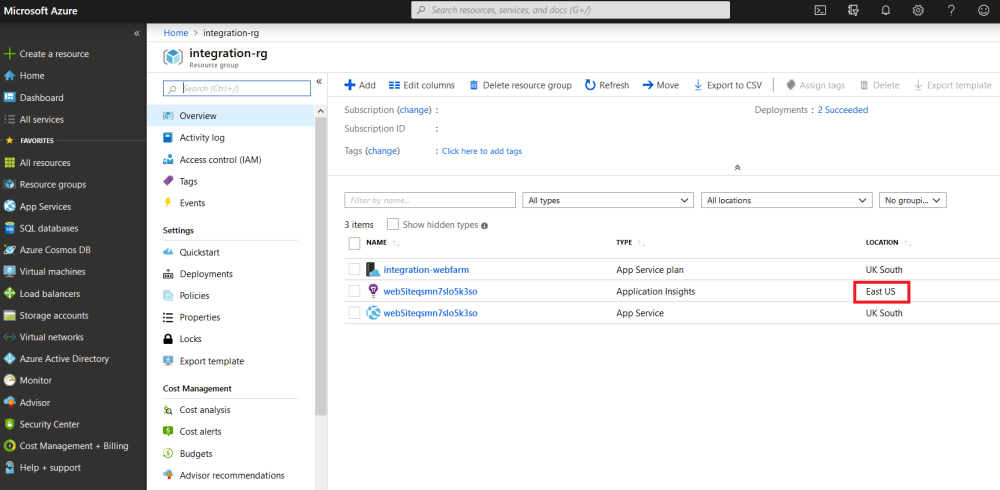
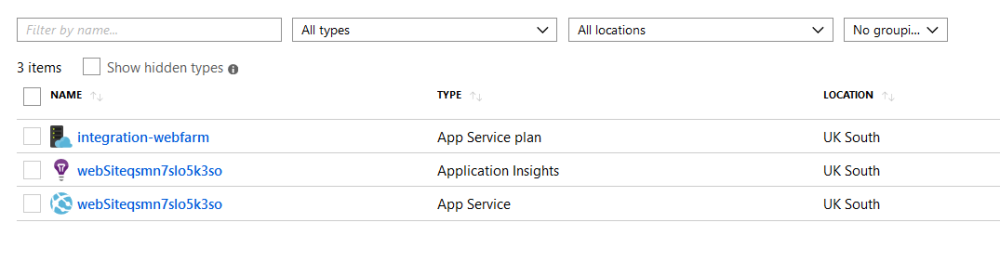
After I create an Azure Pipeline to deploy this infrastructure, I can use the Azure Portal to look at the environment variables for my website by clicking on the app service, and looking in the “Configuration” item, as shown in the image below. This shows that there is now an environment variable called “ASPNETCORE_ENVIRONMENT”.
And I can access the environment variable’s parameter in C# using the code below:
Environment.GetEnvironmentVariable("ASPNETCORE_ENVIRONMENT")
This is a tremendously powerful technique when creating infrastructure.
Another example is one I mentioned in the introduction – consider when you’re creating a website that uses something like Azure Key Vault to hold connection strings. As I’ve talked about in my last post, you might want the name of the Azure Key Vault to be automatically created during the pipeline with a unique name.
But if I don’t know the name of the key vault when I’m developing my code, how can I refer to it from my code? A common approach is to specify resource names in a configuration file, but if we can’t be sure of the name of the resource until after it has been created, this means we’d have to modify the config file after deployment.
Instead, my approach is:
- Refer to an environment variable called something like “AZURE_KEY_VAULT” in my code
- Create the Azure Key vault with a unique name using an ARM template
- Add an environment variable section which depends on the successful creation of the Azure Key Vault, and update the “AZURE_KEY_VAULT” environment variable with the unique name of the Azure Key Vault.
Now as a developer, I never need to care about what any environment’s key vault name is, and I can happy tear any environment down without worrying about having to manually update or references to resources which might have changed name when I spin it back up – I just need to refer to the name of the environment variable, without ever having to worry about its contents.
The code below shows what my appsettings resource looks like for this scenario:
"resources": [
{
"name": "appsettings",
"type": "config",
"apiVersion": "2015-08-01",
"dependsOn": [
"[resourceId('Microsoft.Web/sites', variables('webSiteName'))]",
"[resourceId('Microsoft.KeyVault/vaults', concat('myKeyVault-', uniqueString(resourceGroup().id)))]"
],
"tags": {
"displayName": "appsettings"
},
"properties": {
"AZURE_KEY_VAULT": "[concat('myKeyVault-', uniqueString(resourceGroup().id))]"
}
}
]
Wrapping up
This has been quite a long post about quite a simple concept – automatically create environment variables in your website for all the Azure resources it uses, and then automatically populate the values of those variables while those resources are being created. But it’s a worthwhile technique to employ – I’ve found this makes spinning up and tearing down environments in one step much easier, rather than having a multi-step process of creating infrastructure, noting the name of resources created, and then updating and deploying XML/JSON configuration files.







































You must be logged in to post a comment.